|
Future Therapies
Advanced
Speech Encoding
One system, being developed
for
DARPA by Rick Brown of Worcester Polytechnic Institute in Massachusetts,
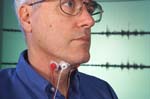
relies on a sensor worn around the neck
called a
tuned electromagnetic resonator collar (TERC). Using sensing techniques
developed for magnetic resonance imaging, the collar detects changes in
capacitance caused by movement of the vocal cords, and is designed to
allow
speech to be heard above loud background noise.
DARPA is also pursuing
an
approach first developed at NASA's Ames
lab, which involves placing electrodes
called
electromyographic sensors on the neck, to detect changes in impedance
during
speech. A neural network processes the data and identifies the pattern
of
words. The sensor can even detect subvocal or silent speech. The speech
pattern
is sent to a computerised voice generator that recreates the speaker's
words.
DARPA envisages issuing
the
technology to soldiers on covert missions, crews in noisy vehicles or
divers
working underwater. But one day civilians might use a refined version
to be
heard over the din of a factory or engine room, or a loud bar or party.
More
importantly, perhaps, the technology would allow people to use phones
in places
such as train carriages, cinemas or libraries without disturbing
others. Brown
has produced a TERC prototype, and an electromyographic prototype is
expected
in 2008.
However, both systems
come at a
cost. Because the words are produced by a computer, the receiver of the
call
would hear the speaker talking with an artificial voice. But for some
that may
be a price worth paying for a little peace and quiet.
NASA
scientists have begun to computerize human,
silent reading using nerve signals in the throat that control speech.
In
preliminary experiments, NASA scientists found that small, button-sized
sensors, stuck under the chin and on either side of the ‘Adam’s apple,’
could
gather nerve signals, send them to a processor and then to a computer
program
that translates them into words.
"What
is analyzed is silent, or sub-auditory,
speech, such as when a person silently reads or talks to himself," said
Chuck Jorgensen, a scientist whose team is developing
silent,
subvocal speech recognition at NASA Ames Research Center in
California’s
Silicon Valley.
To learn
more about what is in the
patterns
of the nerve signals that control vocal chords, muscles and tongue
position,
NASA Ames scientists are studying the complex nerve signal patterns.
"We
use an amplifier to strengthen the electrical nerve signals. These are
processed to remove noise, and then we process them to see useful parts
of the
signals to show one word from another," Jorgensen said.
the signals are amplified,
computer
software ‘reads’ the signals to recognize each word and sound. "We use
neural network software to learn and classify the words," Jorgensen
said.
"It’s recognizing the pattern of a word in the signal."
In their first experiment, scientists ‘trained’ special software to
recognize
six words and 10 digits that the researchers ‘repeated’ subvocally.
Initial
word recognition results were an average of 92 percent accurate. The
first
sub-vocal words the system ‘learned’ were ‘stop,’ ‘go,’ ‘left,’
‘right,’
‘alpha’ and ‘omega’ and the digits ‘zero’ through ‘nine.’ Silently
speaking
these words, scientists conducted simple searches on the Internet by
using a
number chart that represents the alphabet to control a Web browser
program.
"We took
the alphabet and put it
into a
matrix -- like a calendar. We numbered the columns and rows, and we
could
identify each letter with a pair of single-digit numbers," Jorgensen
said.
"So we silently spelled out ‘NASA’ and then submitted it to a
well-known
Web search engine. We electronically numbered the Web pages that came
up as search
results. We used the numbers again to choose Web pages to examine. This
proves
we could browse the Web without touching a keyboard," Jorgensen
explained.
Jorgensen
and his team developed a
system
that captures and converts nerve signals in the vocal chords into
computerized
speech. It is hoped that the technology will help those who have lost
the
ability to speak, as well as improve interface communications for
people
working in spacesuits and noisy environments.
The work is similar
in principle
to how
cochlear implants work. These implants capture acoustic information for
the
hearing impaired. In Jorgensen’s experiment the neural signals that
tell the
vocal chords how to move are intercepted and rerouted. Cochlear
implants do it
the other way round, by converting acoustic information into neural
signals
that the brain can process. Both methods capitalize on the fact that
neural
signals provide a link to the analog environment in which we live.
|
|


|